- 0 前書き
- 1 用語の説明
- 2 研究デザインの用語の説明
- 3 我々を惑わす罠(思いつく限り)一覧
- ・因果関係があるからといって、相関関係があるとは限らない
- ・相関関係があるからといって、因果関係があるわけではない
- ・疑似相関その1~~因果関係の向きが逆、あるいは循環している~~
- ・疑似相関その2~~交絡因子~~
- ・疑似相関その3~~バークソンのパラドックス~~
- ・「統計的有意差あり」は本当にただの偶然かもしれない
- ・同じ実験を何度も繰り返せば、「統計的有意差あり」の結果が高確率で含まれる
- ・出版バイアス
- ・研究者の立場が、研究の内容や結果に影響を与えることが往々にしてある
- ・データが主観的な指標の場合、人間の意図が結果に影響している
- ・想定したモデルが現実離れしている
- ・複数の原因が重なり合って一つの結果を生み出すとき、ランダム化比較試験ですら役に立たないかもしれない
- ・母集団の選び方&サンプルの選び方が、主張の根拠として不適切な場合がある
- ・外れ値ではないデータが外れ値として除外されているかも
- ・データを不自然に分けている研究には要注意
- ・コントロール群がなくても、因果関係があるかのように見えることがある
- ・同じデータが元であっても、何を比較するかによって印象が大きく変わることがある
- ・過去に当てはまる法則が未来にも当てはまるかどうかわ分からない
- ・実験の対象となった母集団と性質が違う集団には、実験の結果を適応できない
- ・観測する変数の分散の大きさ次第で、相関が出たりでなかったりする
- ・回帰直線を引くことに意味はあるのか。検討すべき
- ・時系列データでは、時間とともに条件が変化しているかもしれない
- ・細かすぎる数字には用注意。誤差を評価していない可能性が高い
- ・「○○の△%は××で決まる」みたいな話は、同じ条件をそろえなければ再現されない&変数の独立性が必須
- ・集計してから判断したのか、判断してから集計したのか
- 4 研究デザインと証拠能力について
- 5 参考文献
0 前書き
「我々を惑わす罠一覧」がこの記事を書こうと思った理由だったりします。
データの解釈・論文とタイトルに書きましたが、この記事は、疫学・薬学・心理学・社会学・経済学などの分野を想定しています。物理・数学・化学・工学などの分野や、科学ではない分野は、この記事では想定していません。
1 用語の説明
・擬似相関 - Wikipedia
・交絡 - Wikipedia
交絡(こうらく、英: Confounding)は、統計モデルの中の従属変数と独立変数の両方に(肯定的または否定的に)相関する外部変数が存在すること。そのような外部変数を交絡変数(confounding variable)、交絡因子(confounding factor、confounder)、潜伏変数(lurking variable)などと呼ぶ。したがって科学的研究では、第一種過誤(従属変数が独立変数との因果関係にあるという偽陽性の結論)と呼ばれるこれらの要因を避けるよう制御する必要がある。2つの観測された変数のそのような関係を擬似相関という。すなわち交絡が存在する場合、観測された現象の真の原因は交絡変数であるにもかかわらず、独立変数を原因と推論してしまう。
・出版バイアス - Wikipedia
2 研究デザインの用語の説明
・横断研究 cross-sectional study - 日本理学療法士学会
ある特定の対象に対して,疾患や障害における評価,介入効果などを,ある一時点において測定し,検討を行う研究です.過去にさかのぼったり,将来にわたって調査したりはしません.利点としては,時間的・経費的な効率が良く,いくつかの要因に着目して比較でき,様々な要因を一度に測定し,検討できるなどの点があげられます.欠点としては,バイアスの影響が入りやすく,原因と結果の因果関係が明確ではないなどの点があげられます.
・縦断研究 longitudinal study - 日本理学療法士学会
研究を時間要因によって分類したときの一つで,横断研究のように現時点での暴露の有無・程度を調べるのではなく,過去にさかのぼって,または将来にわたって,ある特定の対象に対して暴露の有無などを調査し,ある程度の期間を経たデータをとる研究です.
後ろ向き研究(症例対照研究)と前向き研究(コホート研究・ランダム化比較試験(RCT))が相当します.
・前向き研究 prospective study - 日本理学療法士学会
一定の期間を経て前向きにデータをとる縦断研究の一つです.疾患の起こる可能性がある要因にさらされるかどうかに注目して群分けし,研究を開始してから将来(数ヵ月後,数年後)にわたって追跡を続け,疾病などの発生状況を比較する研究方法です.研究を開始する時点で,交絡因子などの影響を把握することができるといった利点がありますが,研究を終えるまで,かなりの時間と費用が必要となることが欠点としてあげられます.
ランダム化比較試験(RCT)やコホート研究などが代表的なものです.
前向き研究では、結果を得る前に解析の手法を決めておくことが基本だそうです。
・後ろ向き研究 retrospective study - 日本理学療法士学会
一定の期間を経て後ろ向きにデータをとる,縦断研究の一つです.研究を開始する時点から,過去にさかのぼって疾患や障害を引き起こした要因(人工股関節全置換術を施行された患者における転倒など)にさらされたかどうかを調べる方法です.起こったことを振り返って確認するので,交絡因子の把握が困難ですが,研究を終えるまでに要する時間が,比較的短時間ですむことが可能です.症例対照研究などが代表的なものとなります.
・観察研究 observational study - 日本理学療法士学会
人為的,能動的な介入(治療行為等)を伴わず,ただその場に起きていることや起きたこと,あるいはこれから起きることをみるという研究方法です. 観察研究は,その場で起きていることを断面的に調査すれば横断研究,過去にさかのぼって起きたことを調査すれば症例対照研究,これから起きることを調査すればコホート研究と分類されます.
・ランダム化比較試験 - Wikipedia
ランダム化比較試験(ランダムかひかくしけん、RCT:randomized controlled trial)とは、評価のバイアス(偏り)を避け、客観的に治療効果を評価することを目的とした研究試験の方法である[2]。根拠に基づく医療(EBM:evidence-based medicine)において、このランダム化比較試験を複数集め解析したメタアナリシスに次ぐ、根拠の質の高い研究手法である[2]。主に医療分野で用いられているが、経済学においても取り入れられている[注釈 1][3]。無作為化比較試験 とも呼ばれている[4]。
改善度に関する主観的評価を避けるための尺度であるエンドポイントを用いる、効果の差を計測するための治療していない偽薬などを施した群を用意する、二重盲検法によって研究者がどちらが治療群かわからないようにし、治療群と対照群をランダムに割り当てるといった手法をとる[2]。
前向き研究の一つです。
・非ランダム化比較試験(NRCT)|"健康を決める力"用語集
臨床研究では治療群(治療を行う群)と対照群(治療をせず観察のみの群)の2つに分けて比較するが、2つの群に分ける際に無作為ではなく分けている研究を指す。たとえば主治医、病棟、病院など恣意的に治療群と対照群を割り付けられることで、両者の性質に偏りが生じやすくなり、結果に影響が生じる恐れがあるためランダム化比較試験よりもエビデンスレベルが低いとされている。
明言された記述を見つけることができませんでしたが、おそらく前向き研究の一つと考えていいと思います。
・二重盲検法 - Wikipedia
二重盲検法(にじゅうもうけんほう、英: Double blind test)とは、特に医学の試験・研究で、実施している薬や治療法などの性質を、医師(観察者)からも患者からも不明にして行う方法である。プラセボ効果や観察者バイアスの影響を防ぐ意味がある。この考え方は一般的な科学的方法としても重要であり、人間を対象とする心理学、社会科学や法医学などにも応用されている。この盲検化を含んだランダム化比較試験(RCT)は、客観的な評価のためによく用いられる。
行為の性質を対象である人間(患者)から見て不明にして行う試験・研究の方法を、単盲検法という。これにより真の薬効をプラセボ効果(偽薬であってもそれを薬として期待することで効果が現れる)と区別することを期待する。しかしこの方法では観察者(医師)には区別がつくので、観察者が無意識であっても薬効を実際より高くまたは低く評価する可能性(観察者バイアス)や、患者に薬効があるかどうかのヒントを無意識的に与えてしまう可能性が排除できない。そこでこれをも防ぐために、観察者からもその性質を不明にする方法が二重盲検法である。
・メタアナリシス - Wikipedia
メタアナリシス(meta-analysis)とは、複数の研究の結果を統合し、より高い見地から分析すること、またはそのための手法や統計解析のことである。メタ分析、メタ解析とも言う。ランダム化比較試験(RCT)のメタアナリシスは、根拠に基づく医療 (EBM) において、最も質の高い根拠とされる[2]。
メタアナリシスという言葉は、情報の収集から吟味解析までのシステマティック・レビューと同様に用いられることがある[3]。厳密に区別する場合、メタアナリシスはデータ解析の部分を指す[3]。また、メタアナリシスとシステマティックレビューをまとめてリサーチ・シンセシスとも言う。
メタアナリシスとシステマティックレビューの違いはあまり明確ではないようですが、こちらの記事によると
結論から言うとシステマティックレビューとメタアナリシスの違いは、
システマティックレビュー:課題に関してプロトコールに従った文献調査・選択、評価し、結果を統合し、課題に対する批評を行う総説
メタアナリシス:課題に関してプロトコールに従った文献調査・選択、評価し、統計学的な手法を用いて定量的に結果を統合・提示する
システマティックレビューとメタアナリシスの定義はあいまいなので別のところでは異なる説明がなされているかもしれません。
システマティックレビューは定性的でメタアナリシスは定量的ともいえます。
システマティックレビューではエビデンスの質を重要視するのに対して、メタアナリシスは定量的に結果を表すために統計学的な手法を使います。
だそう。どちらも証拠能力が高いことは間違いないですが、メタアナリシスの方がやや優勢のようです。
一次研究の俯瞰的分類
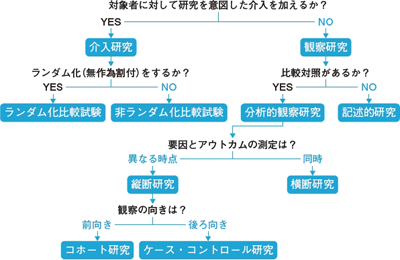
画像はこちらの記事から拝借しました
3 我々を惑わす罠(思いつく限り)一覧
勘違いや思い込みの種になりそうなバイアスを思いつく限り列挙します。もちろん、これらが気を配るべきバイアスの全て、ではありません。
・因果関係があるからといって、相関関係があるとは限らない
これは直感的には分かりにくいですが、例えば以下のような場合を表します。
観測した変数W,Zと観測していない変数X,Yを考え、因果関係の向きが W → (X,Y) → Z ということにします。
X = - W + noise_X
Y = W + noise_Y
Z = X + Y + noise_Z
(noiseは正規分布の乱数とする)で表現できるとすると、実質、
Z = noise_X + noise_Y + noise_Z
と表現されることとなり、ZとWの相関関係はないが、因果関係はあるということになります。
・相関関係があるからといって、因果関係があるわけではない
下で言及する疑似相関の影響で、相関関係があっても因果関係がない場合が頻出します。
・疑似相関その1~~因果関係の向きが逆、あるいは循環している~~
そのままの意味です。変数Xと変数Yを観測し、相関が確認されたとき、因果関係の向きがX→Yで説明できたつもりでも、現実はY→Xだった可能性があります。あるいは、X→Y と同時に Y→X だったということもあり得ます。もちろん、時系列などの理由で常識的に考えて、どちらかに確定できる場合もあります。
・疑似相関その2~~交絡因子~~
観測した変数XとYの間に相関がるものの、XとYの間に因果関係がない場合もあります。共通の因子Tからの影響をX,Yが受けている場合です。観測した2変数間に相関があって、それっぽい因果関係の説明ができたとしても、交絡因子が存在する可能性は残されています。
「メタボ検診に行った人の方が、その翌年の体重が減少していた。メタボ検診がダイエットに効果があるように見える。ところが実際は、検診に行く人が健康志向が強く、健康的な生活をしていただけで、検診に効果があったわけではない。」みたいな話です。実際そのような研究があるそうです。ここでは、メタボ検診に行ったかどうかを表す変数X、体重の減少量を表すY、健康志向の強さを表す共通の因子T、という座組になります。
一般に、交絡因子を取り除くためにはランダム化比較試験を用いる必要があります。観察研究や非ランダム化比較試験では、交絡因子は排除できません。
・疑似相関その3~~バークソンのパラドックス~~
3つの観測変数X,Y,Zを考え、本当の因果関係の向きが X,Y→Z 、3つの変数の間の関係をZ = X + Y + noise で表現できる仮定します。X, Y, noiseがいずれも平均0、分散1の正規分布に従うことにします。
そのうえで重大な操作を行います。母集団の中からZ>0の場合だけを選んで新しい母集団をつくるのです。すると新しい母集団において、XとYの間には疑似相関が表れます。このような疑似相関の現れ方をバークソンのパラドックスと呼ぶそうです。
とあるシンクタンクにおける新人採用試験を想像してください。採用試験で評価される項目は2つです。一つ目の項目Xは、新人候補の「同僚と協力して問題解決する能力の得点」です。二つ目の項目Yは、「その人の専門分野の能力の得点」とします。なお、XとYは互いに独立なことが確かめられていることとします。
そのシンクタンクの新人採用基準が「Z=X+Yとしたとき、Zが0より大きいこと」だったとします。すると、採用された新人を母集団とするとき、XとYに負の相関が表れることとになります。(専門分野の能力が高い人ほど、同僚と協力するのが苦手という傾向。)
合流点での選抜は、母集団の選び方の妥当性を検討するための項目の一つだと思います。あなたはどのように考えますか?
・「統計的有意差あり」は本当にただの偶然かもしれない
厳密にいえばバイアスではありませんが、リストアップしておきます。ある程度数学を理解しないと、統計的有意差の意味は分からないと思います。少なくとも私には、言葉だけで正確なニュアンスを伝えることはできません。知らない方はご自分で勉強してください。(ネットの無料の情報だと、私はこれしか知りません。【大学数学】推定・検定入門①(母集団と標本)/全9講【確率統計】 - YouTube)
・同じ実験を何度も繰り返せば、「統計的有意差あり」の結果が高確率で含まれる
欲しかった結論を得るために(?)似たような実験が何度も何度も行われると、いつか統計的有意を示す研究が出現するでしょう。逆に有意差無しの研究も出てきます。その結果がたとえただの偶然だとしても、実験結果は本物で解析手法も妥当、なんて話になりえます。
出版バイアスとコンボにすると、とてもタチが悪いバイアスになります
・出版バイアス
「特に効果はありませんでした。」と主張する論文がジャーナルを飾る可能性は低いですよね。出版社もアホではありません。画期的に見える研究を乗せたがるはずです。「効果なし」の方が頻繁に発生していたとしても、我々が読む論文が「効果あり」ばかりかもしれません。上の
・同じ実験を何度も繰り返せば、「統計的有意差あり」の結果が高確率で含まれる
とコンボにすると、かなりタチが悪いバイアスです。
・研究者の立場が、研究の内容や結果に影響を与えることが往々にしてある
多くの研究者は、民間企業で雇われていたり、行政で雇われています。研究者自身が仕事を追われかねない行動をとる可能性は低く、逆に、出世したり給料が増えたりする行動をとる可能性は高いです。結果、研究者自身とその所属組織が喜ぶ結果は公表されやすい一方、都合の悪い結果は日の目を浴びにくいものです。科研費をもらえるような研究しかしないのも、仕方ありません。研究者自身が所属する組織の利害関係や、予算を決定する人間の意志なども論文の内容や結論に影響することを忘れてはなりません。
しょうがないじゃないか、にんげんだもの。
・データが主観的な指標の場合、人間の意図が結果に影響している
「因果関係を証明できない」というシロ魔法の呪文を唱えれば、状況的に十中八九影響が表れていたとしても、何もなかったことにできます。逆に「起こったことを正確に」というクロ魔法の呪文を唱えれば、全く関係なく起こった出来事も因果関係を説明しているように見せることができます。
X%が効果を実感しました?そんなのは質問する場面を変えたり言い回しを工夫したりすれば、いくらでも数字が上下するでしょう?
ってわけで。ひねくれた見方と素直な見方を両方試すことをお勧めします。まる。
・想定したモデルが現実離れしている
これは言葉のままの意味です。モデルを使ってフィッティングする時は、そのモデルがどの程度妥当か評価しなければ、偉い人に鼻で笑われること間違いなし。
例えば因子分析などの線形回帰モデルを使った場合、現実は非線形な関係だったとしてもそれっぽい結論を無理やりはじき出します。私の過去の記事、PyMC3でMCMCしてみた。線形一次のモデルへのアンチとして。でも似たようなことを言及しているので、興味があれば参考にどうぞ。あまりお勧めはしませんが。
・複数の原因が重なり合って一つの結果を生み出すとき、ランダム化比較試験ですら役に立たないかもしれない
以下は、架空のたとえです。最後まで読んでいただければ、何が言いたいか理解していただけると思います。
とあるアレルギー(以降キテレツアレルギーと呼ぶ)の発症の有無を表す変数Z(Z=0,1)が、二つの変数X,Y(X=0,1 Y=0,1)を用いて、Z = XY と表現できると仮定します。キテレツアレルギーの原因はXとYの二つが想定されなければなりません。そして、人類はまだそのことを知らないこととします。
Xをその人が住んでいる環境に起因する変数、例えば「自動車の排気ガスに含まれる有機物が、大気中に一定以上の濃度で含まれているかどうか」だったとします。ほとんどの地域で100年前は0、現在は1ということにします。
一方の変数Yを例えば、「その人の食べ物に一定以上の量の炭水化物(米・小麦など)が含まれるかどうか」だったとします。こちらは昔も今も Y = 0 の人が5割、Y = 1 の人が5割だったとします。
そんな条件の下、現代の研究者が Z と Y の関係を調べ、「キテレツアレルギーの原因は炭水化物の取りすぎだ」と結論付けたとしましょう。すなわち、Z = Y だと結論付けたのです。現代ではX=1ですから、間違ってはいません。しかし、100年前に同じ研究をしたら、Z=0 (∵X=0)となり、「キテレツアレルギーなどというものは存在が確認されていない都市伝説なのだから、炭水化物の摂取量とアレルギーの発症は関係ない」との結論になっていたでしょう。
このたとえ話の、100年前の研究や現代の研究者は、適切な母集団を選んでまともな実験デザインを使用し、滞りなく解析し結論したとしても、変数Xの存在を想定しない限り真実を明らかにすることができないのです。一次研究の中で最も証拠能力が高い実験デザインとされているランダム化比較試験であっても、それは変わりません。
因子分析などの線形回帰分析を用いた場合も同じです。人為的に操作できる変数x,y と 観測された変数 z の因果関係が、状況的に見て明らかに(x, y) → z だった場合を考えてみましょう。x, y, z 全ての変数が平均0分散1に正規化したとき、 z = ax + by + noise で表現される、と結論付けたとします。ここで、何らかの理由で、人為的に操作できる変数xの正規化前の定義域が、本来操作できる範囲よりもはるかに小さかったとします。すると、 z = ax + by + noise の a の値は、xの操作できる範囲をフルに使った場合と比べてはるかに小さくなります。「○○が結果の△%を決定している」という類の統計に基づく調査結果は、その調査とそっくり同じ条件でのみ成り立つということに注意しなければなりません。
・母集団の選び方&サンプルの選び方が、主張の根拠として不適切な場合がある
その母集団やサンプルは、ランダムに選ばれたものなのか、それとも特定の性質をもつものが多く集められているのか。その答え次第で、データの分析・解析結果から主張できることも変わります。
よくあるパターンの一つが、時系列データを用い分析するときに特定の部分だけを観測したり使用したりすることで、事実と真逆の主張が展開されるというものです。
・外れ値ではないデータが外れ値として除外されているかも
外れ値は、判断を誤らせることがあるため、無視した方が良い場合もあります。データの選択的な除外自体は悪ではありません。何が目的でデータを使うかによっても、外れ値判定の基準は変わるかもしれません。問題は、除外されたデータが外れ値ではなかった場合です。それは本当に除外してよかったデータなのか。はっきりしない場合は、導き出された結論を疑ってみるべきでしょう。
・データを不自然に分けている研究には要注意
データの分け方が不自然な研究は、その結論を大いに疑ってかからなければいけません。統計的検定の結果を慎重に選んで、都合のいい部分、都合の良い組み合わせだけを報告している可能性が高いからです。私の経験だと、「インフルエンザワクチンの効果を測るランダム化比較試験」を名乗る論文に変なのがチラホラと。。。。。だからって、ワクチンに効果がないとは思いませんけどね。いぇ、毎年摂取していたのに何度も感染した人を知ってるし、何十年も摂取していないのにその間感染しなかった人も知っていますが、ワクチンには絶大な効果があると思いますよ。えぇ、もちろん。
・コントロール群がなくても、因果関係があるかのように見えることがある
反事実を想定しない調査(記述的研究)では、因果関係を証明できません。しかし、あたかも因果関係があるかのように見えることがあります。
かつて、胃冷却法なるものが使われていました。胃冷却法とは、胃潰瘍の治療法の一つで、胃にバルーンを挿入して、そこに冷却された液体を注入するという方法です。1950年代に進められた研究で、胃酸の分泌が抑えられ、痛みも減ったという報告がありました。この結果が権威ある医学雑誌「ジャーナル・オブ・ザ・アメリカン・メディカル・アソシエーション」に掲載され、胃冷却法はしばらくの間使われました。ところがこの報告は、比較するグループが無かったため、実際はその効果を示せていなかったのです。
ちなみに、胃冷却法の有効性を確かめるため、冷却した液体を注入するグループと体温の液体を注入するグループに分けて実験したところ、冷却した液体を注入された患者の34%、常温の液体を注入された患者の38%の改善が報告されたそうです。プラシーボ効果だったんですね。
・同じデータが元であっても、何を比較するかによって印象が大きく変わることがある
例えば、絶対値を比べた場合と変化量を比べた場合、変化率を比べた場合など、比べ方は様々です。何の意図をもって何を比べているのか、注意して考えましょう。
グラフの書き方次第で印象が変わることも多いです。変化を強調するような縦軸のレンジになっていないか?折れ線グラフは横軸等間隔で推移しているか?何の意図をもって何を比べているのか、確かめることが重要です。
・過去に当てはまる法則が未来にも当てはまるかどうかわ分からない
とある投資家が漏らした示唆的な言葉を引用します。
市場タイミングに関する興味深いアプローチをいろいろ見てきて、40年間の運用でそのほとんどを試してみた。しかし、自分がやる前は偉大な方法であったかもしれないが、私のときには、どれ一つとしてうまくいかなかった。何一つ!
これが、後ろ向き研究の証拠能力が低い理由(の一つ)です。つまり、無数の選択肢から偶然有意差が出たものをピックアップしたところで、それはあくまで偶然だということです。
・実験の対象となった母集団と性質が違う集団には、実験の結果を適応できない
読んで字のごとく。極端な話、動物実験が根拠として弱いのもこれですよね。ほかにも、遺伝子組み換えや製薬などでよくある話ですが、「試験期間2年間で悪い影響が確認できなかったので安全です」といって、まだ何年何十年も生きる人に勧める、みたいな感じですね。もしかしたら20年後に心臓病やガンなどが激増するかもしれませんが、そんなことは実験していないから無視するのです。....陰謀論じゃないですよ?だって、少しも陰で行われる謀じゃないですから。私としては、公的な機関でも構わないから、人種や生活習慣の多様な集団を用意して何十年の追跡を行うRCTを乱用してほしいんです。食習慣が崩壊していても運動習慣がなくても、2・3年で糖尿病になる人は滅多に居ないのですから。
・観測する変数の分散の大きさ次第で、相関が出たりでなかったりする
原因Xと結果Yが、Y = X + noise (noiseは平均0、標準偏差1の正規分布に乗ったノイズ)で表される場合を考えます。 Xの取りうる値の範囲が狭い時ほど決定係数が0に近づき、Xの取りうる値の範囲が広い時ほど決定係数が1に近づきます。母集団の取り方次第で、特定の変数の分散が小さくなり、相関が現れない、なんてこともあり得ます。
・回帰直線を引くことに意味はあるのか。検討すべき
直線に乗らない事象にもかかわらず、回帰直線を引いて傾きがどうこう、と議論していないでしょうか?そもそも回帰直線を用いて議論すること自体に意味があるかどうかを注意しつつ、回帰直線を用いた議論を検討する必要があります。
・時系列データでは、時間とともに条件が変化しているかもしれない
推移を表すグラフが急に大きく変化したら、集計上の定義の変化を疑うべきです。推移のグラフを見るときに気を付けるのはもちろん、「過去3か月のデータによると、○○の人の方が出来事の前後で××倍になった。」みたいな主張にも注意が必要です。例えば、
まず、一か月の時点で集計されるデータの定義が変わったとします。
二か月の時点で、全員に共通の出来事があり、○○になる確率が変わったとします。
最初の1か月は、○○の人が1000人
基準が変わった次の1か月は、○○の人が10人
共通の出来事があった以降の最後の1か月は、○○の人が20人
だったとします。共通の出来事以降の○○の人数は、それ以前の○○の人数の2%弱だったことなります。
共通の出来事が○○の人数を減らしたと言えるでしょうか?言えません。ですが、「基準が変わった」という情報を知らず、最初の2か月と最後の1か月を比較した場合、共通の出来事に○○の人数を減らす効果があったように見えることでしょう。
・細かすぎる数字には用注意。誤差を評価していない可能性が高い
国勢調査のような大規模で集計漏れが予想されるデータでは、細かすぎる数字に注意が必要です。5桁の数字なのに「約」がついていないとか、母集団が5桁に対して2桁以下の数字が主張される時など。
・「○○の△%は××で決まる」みたいな話は、同じ条件をそろえなければ再現されない&変数の独立性が必須
Z=X+Y で3変数の関係が表現でき、XとYが独立、かつ、因果関係の向きが(X, Y)→Z のときを考える。
ZはXで20%説明可能で、Yで80%説明可能
となる。
実験条件を変え(前回までは日本人大学生だけで母集団を作っていたけど、今回は国籍不問の20~70歳をまんべんなく集めた、みたいなこと)、Xの標準偏差が3,Yの標準偏差が4になったとする。このとき、
ZはXで36%説明可能であり、Yで64%説明可能
となる。○○は△%遺伝で、◇%運や環境で、×%が努力です、みたいな説明は、実験条件と同じ環境の世界でしか成り立たないし、遺伝と環境と努力が互いに影響を及ぼさない保証がなければいけない。
・集計してから判断したのか、判断してから集計したのか
同じ統計データであっても、
①個別の事例に対して判断して、その判断の結果を集計して統計にする場合(死因別の死者数の統計など。死んだ理由を判断することは、本質的に主観的)
と、
②誰でも同じ判断ができる事例を集計して、その集計結果から何かを判断する場合(「全死者数と行方不明者数の合計」や「超過死亡数」など)
で、適切な解釈方法は全く異なる。
個別の事例に、誰でもできる正確な判断基準を適応できる場合、すなわち①の場合、統計上の特定の数字が、実態よりも極端に大きくなったり小さくなったりする。判定の実態を詳しく知っていることが、統計を解釈するための必須事項になる。
4 研究デザインと証拠能力について
4-1 証拠能力のピラミッド
「金や名誉に目がくらんで実験データを改ざんしました」などの人為的なバイアス(割と重要な視点だと思います)を抜きにして考える場合、研究結果の持つ証拠能力に強さの序列は、下の画像が参考になります。(メタアナリシス - Wikipediaから画像を拝借)
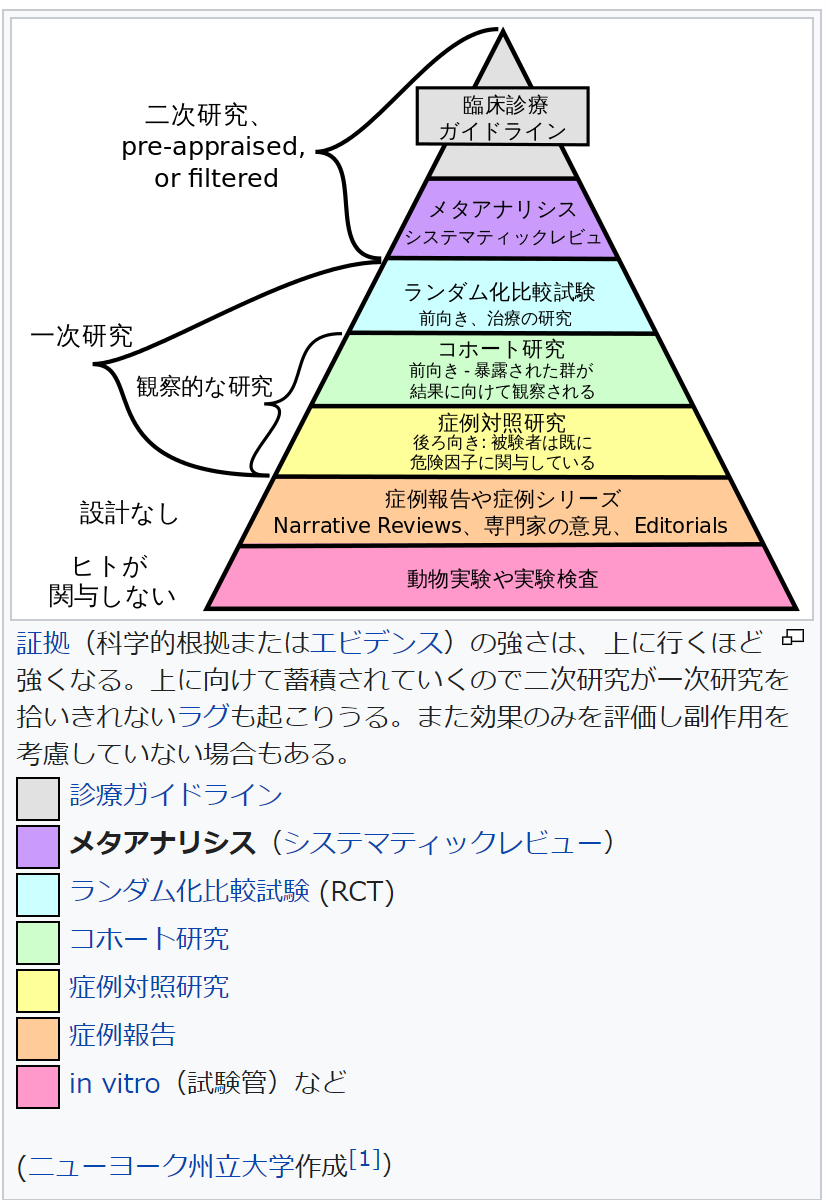
この画像で使われている言葉は、医学とか疫学とか、そっち系の世界を想定していると思われます。ほかの分野ではコホートとか症例とか使わないんじゃないかな。
ピラミッドの上に行けば行くほど証拠能力が高いという目安です。
診療ガイドラインは、関係ない分野を考えるときは無視しましょう。
コホート研究は、前向きの観察研究または非ランダム化比較試験と言い換えます。
症例対象研究は、後ろ向きの観察研究と言い換えます。
医学や疫学以外の分野でも使える言葉で、それぞれの研究デザインの証拠能力を比較すると、以下のような序列になります。
1位:メタアナリシス
(1.5位:システマティック・レビュー)
2位:ランダム化比較試験
3位:前向きの観察研究と非ランダム化比較試験
4位:後ろ向きの観察研究
5位:専門家の意見、記述的研究
?:横断研究
4-2 横断研究の証拠能力について
ニューヨーク州立大学が作成した証拠能力のピラミッドには、横断研究が含まれていないようです。私の個人的な意見では、後ろ向きの観察研究と同程度(=4位)か、後ろ向きの観察研究と専門家の意見・記述的研究の間(=4.5位)くらいが適切だと思うのですが、どうでしょうか?
4-3 後ろ向きの観察研究の証拠能力について
後ろ向きの観察研究は、前向き研究と比べて証拠能力が低いとされます。私の理解する限り、理由は以下の通りです。ほかにも複数あるかもしれません。
後ろ向きの観察研究が、前向き研究と比べて証拠能力が低いとされ理由。それは、「偶然その結論に至った可能性が、前向き研究よりもはるかに高まるから」です。つまり、どういうことか。
後ろ向き研究では、結果に対する原因の候補が、理論上無限に用意できます。本来ならば相関関係や効果量が0の関係であっても、ノイズの乗ったデータの統計である以上、「偶然相関があるように見えた」「偶然効果があるように見えた」ということは起こり得ます。原因の候補が無数にあれば、偶然を引き当てる可能性が高いわけです。
(理由は統計的有意差の意味を知っていれば理解が速いと思います)
4-4 前向きの観察研究の証拠能力について
後ろ向きの観察研究よりも前向きの観察研究の方が、証拠能力が高いとされています。4-3で前述したような、「偶然の結果を引き当てる可能性」が低いからです。
一方で、ランダム化比較試験よりは証拠能力が低いとされます。観察研究は、元々性質が違うグループを比較している可能性が高く、いわゆる「反事実」を想定しているとは言えないからです。
4-5 ランダム化比較試験の証拠能力について
一次研究の中で最も証拠能力が高いとされるのはランダム化比較試験。その真価は、数ある変数の中から特定の変数だけを変化させるられることにあります。これにより、厳密ではないものの、反事実を用意することができるので、ランダム化比較試験は証拠能力が高いとされるのです。
4-6 二重盲検法によるプラシーボ効果の排除について
証拠能力のピラミッドになぜか含まれていないので、二重盲検法への言及を追加しました。二重盲検法は、プラシーボ効果を排除するための手段として用いられています。
ランダム化比較試験を行う際にセットで使われていることがほとんどだ、という認識で合っていると思います(←主観。少なくとも後ろ向き研究では使えない気がする。ランダム化比較試験ではない前向き研究でも、多分使えない?私の勉強不足ゆえ、わかりません)。
5 参考文献
5-1 参考にした書籍
データや論文の解釈に関して詳しく知りたい方は、以下の本を読んでみるといいかもしれません。読んでほしいという意味ではありませんからね?ね? |д゚)