帰無仮説が正しければ、p値の確率分布は一定である
同じ母集団からランダムにサンプルを選び、2つの群を作ったとする。2つの群には、厳密にはサンプルが異なることのほかに、違いを設けない。
このとき、 (p値の意味を理解されている方なら納得していただけるだろうが)、p値の確率分布は0から1の間で一定である。有意水準をp=0.05に定めたならば、5%の確率で有意差を示す。
したがって、「統計的検定を用いるすべての研究が、帰無仮説が正しい場合を扱っていた」と仮定すると、我々が目にする論文に記載されるp値の確率分布は、慣習的に用いられる有意水準p=0.05以下で、一定値をとるはずだ。慣習的に用いられる有意水準p=0.05よりも大きいp値を報告する論文は、表舞台には出てきにくいだろうから、一定値をとると予想されるp値の確率分布の範囲は、あくまでp<0.05の範囲に限定する。
慣習的な有意水準の前後で発表されやすさが変わらないという仮定の下、シミュレーションしてみた。するとやはり、帰無仮説が正しい場合のp値の確率分布を模した折れ線グラフは、一定の値を示した。細かいことを言えば一定ではないが、シミュレーション上どうしても発生する類の誤差だ。気にしないでほしい。
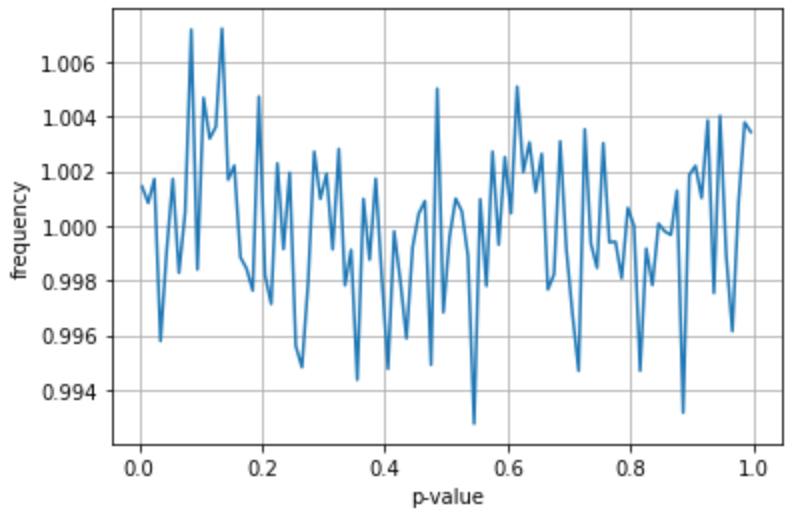
シミュレーションはPythonで行った。コードは注釈*1にて。
効果量が0ではない時の、p値の確率分布
現実的には、統計的検定を用いるほぼすべての研究で、異なる群は何かしら異なる実験条件を伴う。したがって、p値の確率分布は0に偏った分布になりそうだ。解析的な解き方が分からなかったので、シミュレーションして折れ線グラフにしてみた。
・効果量を標準偏差の1/10
・2群のサンプル数がともに100
・2群の標準偏差は等しい
と仮定すると、p値の確率分布は大体こうなる。
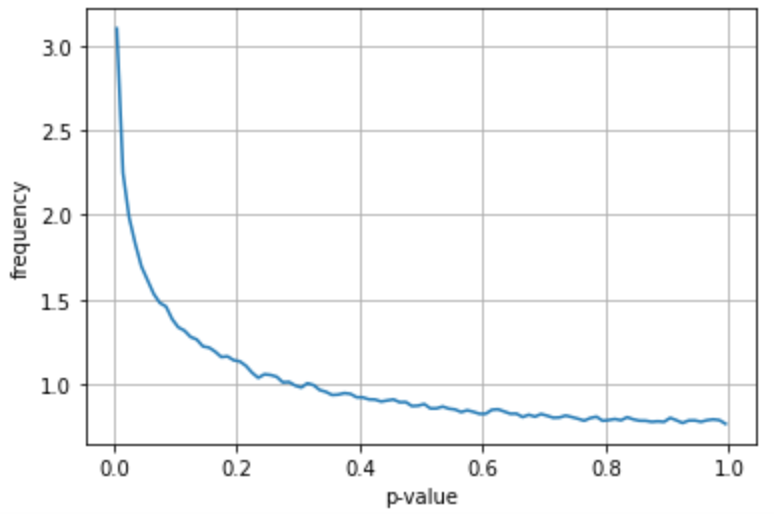
解析的な解き方が分からなかったので、止む無くシミュレーションして折れ線グラフをプロットした。大体の傾向はこれでも十分わかるだろう。
効果量をもっと大きくして、p値の確率分布がどう変わるか見ておく。
・効果量を標準偏差の1/2
・2群のサンプル数がともに100
・2群の標準偏差は等しい
ときの、p値の確率分布は、大体こんな感じ。
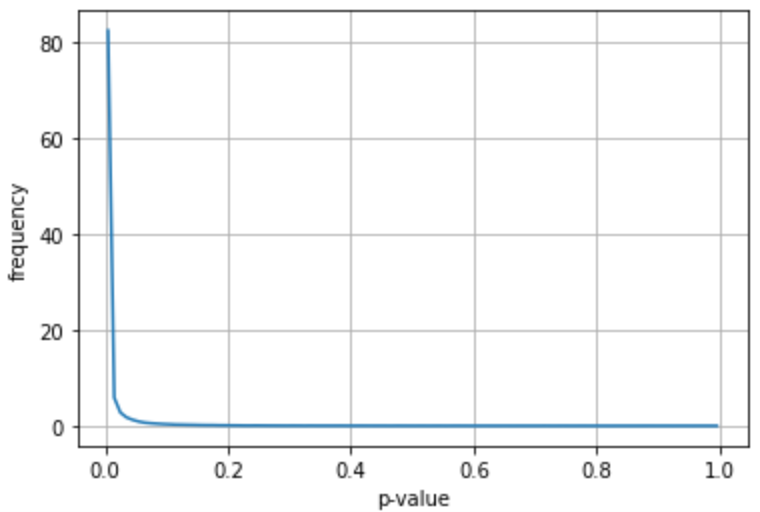
効果量が大きくなれば、p値は小さくなる。当然の結果が確認された。
続いて、効果量も一定ではなく確率分布させてみた。効果量xが確率分布2exp(-x/0.5)に従って出現すると仮定。効果量の確率分布は、プロットするとこうなる。
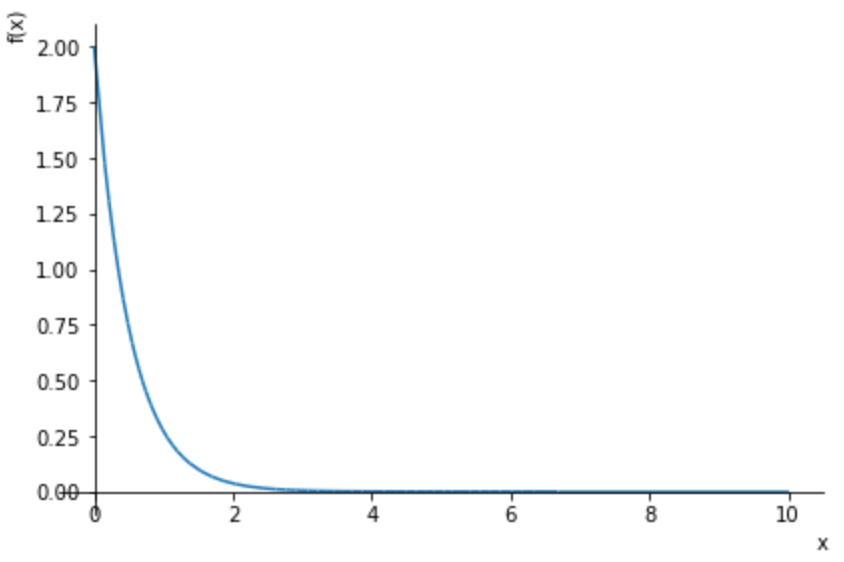
このとき、
・効果量xを確率分布2exp(-x/0.5)
・2群のサンプル数がともに100
・2群の標準偏差は等しい
として、p値の確率分布はおおむね以下の通り。
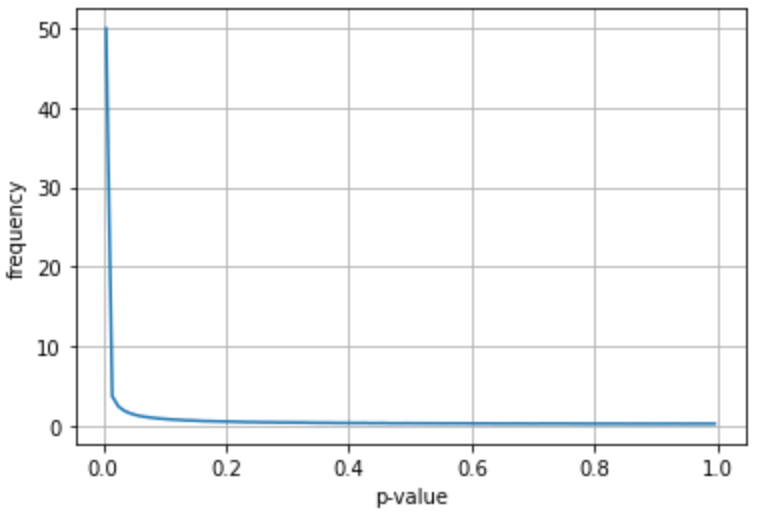
効果量が0ではない時、p値の確率分布は0に偏ることを見てきた。
p値のどの水準で有意差を定義していたとしても、効果量が0ではない研究では、p値の確率分布が0に偏る現象は残るはずだ。
我々の目に届く論文は、どのようなp値の確率分布をとるのだろうか
実際に発表されている論文では、p値は0に偏って分布しているのだろうか?効果量が0ではない事象を多く扱っていれば、p値は0に偏って分布するはずだ。
あるいは一様に分布しているのだろうか?効果量が0の事象ばかりを扱っていれば、p値は一定の確率分布を示すはずだ。
同じような問題意識を持つ同士は大抵どこかに居るものだ。この記事は、「複数の分野において、p値が0.05より少し小さいところで、その近辺のp値をとる頻度が不自然に増える様子」を説明する。報告されたp値は、0の方に偏って分布している。そして、まるでp値が0.05を下回るように操作されたかのような、不自然な確率分布を示すのである。不正の存在の証拠に見えなくもないが、実際はデータを改ざんしたのではなく、p値が0.05を下回るようにデータを「分類」した痕跡ではなかろうか(主観)。年齢は調節したか?期間はそろえたか?.....無意識のうちに誘惑につられて、論文が掲載されやすくなるように有意差を作ってしまったとしても、なにも不思議ではない。研究者の世界は厳しいのだ。
止めは、こちらの論文。
私自身、説明できるほど理解していないので、申し訳ないが、詳しいことを知りたい方は各自読んでほしい。Fig 3.あたりから特に。
公表バイアスは存在する。見えるモノ・見せられたモノだけではなく、見えないモノをも意識したいものだ。
またいつか。




